ラボマニュアル
Manuals
このマニュアルでは、シグモイドフィッティングの方法(EC50)をPPARアゴニストKCLのルシフェラーゼアッセイを例として説明しています。Rはフリーの統計解析ソフトですので、各自のパソコンでデータを解析できます。WindowsでもMacでも使えますが、Macを中心に説明しています。よく分からない場合は、直接聞いてください。
また、Excelについても言えることですが、デフォルトの設定ではグラフの見栄えは良くありません(ラベル等)。ポスター、プレゼン、論文などに用いるような図を作りたい場合は、直接聞いてください。
なお、入力するコマンドは青で示してあります。
2010.4月 大金
データの準備
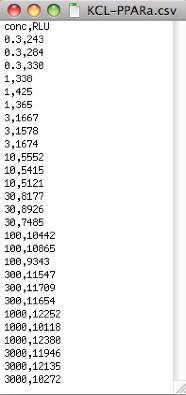
データは、カンマ区切りのcsvファイルとして用意します。エクセル等から保存できます。KCLのアッセイ結果(n=3)のファイルをテキストエディタで開いたものを図に示します。濃度はnMで、RLUはrelative light unitです(ここではバックグラウンドを差し引いていないデータを用いています)。一行目は列名(conc, RLU)です。二行目からデータが並んでいます。このデータはn=3で行った実験のものですので、0.3nMの値が3つ、次に1nMのデータが3つとなっています。生体有機マニュアルページにこのファイルをおいておきますので、実際に試しながら以下を読んで頂きたいと思います。
なお、ファイルを使わずに手入力する場合は、
conc=c(0.3, 0.3, 0.3, 1, 1, 1, 3, 3, 3, 10, 10, 10, 30, 30, 30, 100, 100, 100, 300, 300, 300, 1000, 1000, 1000, 3000, 3000, 3000);
RLU=c(243, 284, 330, 338, 425, 365, 1667, 1578, 1674, 5552, 5415, 5121, 8177, 8926, 7485, 10442, 10865, 9343, 11547, 11709, 11654, 12252, 10118, 12380, 11946, 12135, 10272)
と入力し、以下では「data=dat, 」を省略してください。
データの読み込みとプロット
データの読み込みの前に、作業ディレクトリをcsvのあるフォルダに変更します。ツールバーから「その他」>「作業ディレクトリの変更」とし、csvをおいてあるフォルダを選択してください。
次に、csvファイルを読み込んで、データを「dat」(名前は何でも構いませんが)に入れておきます。
dat = read.table("KCL-PPARa.csv", header=T, sep=",")
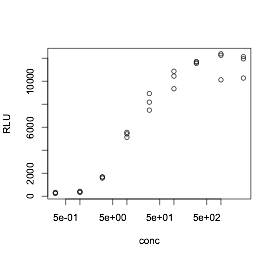
データを見るには、datと入力すれば表示されます。plot(RLU~conc, data=dat)とすることで「RLUをconcで説明する (つまり、y軸にRLU、x軸にconc)」グラフが描けます。濃度のスケールをlogにするには、
plot(RLU~conc, data=dat, log="x")
とします。ここで、およそのEC50、ベースライン、最大値を見ておきましょう。EC50はおよそ20nMほど、ベースラインは200くらい(元のデータも見て)、最大値は12000くらいでしょうか。
シグモイドフィッティング
さて、一般的なシグモイドの式は、次のような形の式です(詳細はどこかで説明します)。RLUをconcで説明するといった形で描いてあります。実際に使うのは、右側のlogを使った式です。
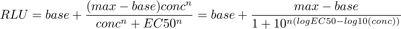
baseはベースライン、maxは最大値、EC50はbaseとmaxのちょうど真ん中となる濃度です。nはHill係数と呼ばれるもので、EC50付近での傾きがの程度を示します。logEC50は、EC50のlog(底は10)です。通常、EC50を見積もる際には、EC50を直接求めるのではなく、logEC50をフィッティングにより求め、その後EC50へ変換します(より正確な信頼区間を求めるのに必要)。
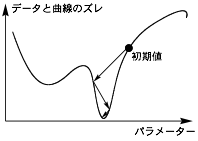
シグモイドの式は、パラメーター(EC50, n)に関して非線形な式です。一般的な直線回帰(線形)の場合はデータを入れるだけで回帰直線が求まりますが、非線形の場合は、パラメーターの初期値が必要となります。非線形の最小二乗法の原理は、基本的には模式図のように、初期値からスタートして最小値(or極小値)に向かって近づいていくものです。ですので、初期値があまりにも外れていると最小値ではなく極小値が求まる、あるいは値が求まらない(収束しない)ということになってしまいます。どの程度の近い初期値が必要かという点ですが、シグモイドの場合はグラフを見て見積もれば十分です。
では、実際にパラメーターを求めてみましょう。EC50はおよそ20nMとグラフから読み取りましたので、logEC50は1.3くらいです(log10(20)と入力すれば計算できます)。Hill係数nの初期値はとりあえず1にしておきます。関数nls()の名前はNonlinear Least Squareの頭文字です。結果は変数「res」に入れておきます。
res=nls(RLU~base+(max-base)/(1+10^(n*(logEC50-log10(conc)))), data=dat, start=c(base=200, max=12000, logEC50=1.2, n=1))
結果を見てみましょう。resと入力すると簡易版の結果がでます。logEC50は1.098と見積もられ、EC50は13nMと求まりました。
res
Nonlinear regression model
model: RLU ~ base + (max - base)/(1 + 10^(n * (logEC50 - log10(conc))))
data: dat
base max logEC50 n
-154.078 11626.035 1.098 1.089
residual sum-of-squares: 9369204
Number of iterations to convergence: 6
Achieved convergence tolerance: 6.254e-06
この結果には、どのような式を用いたかとともに、各パラメーターの見積もりが表示されています。
より詳しくみるには、summary()を使います。
summary(res)
Formula: RLU ~ base + (max - base)/(1 + 10^(n * (logEC50 - log10(conc))))
Parameters:
Estimate Std. Error t value Pr(>|t|)
base -1.541e+02 3.809e+02 -0.404 0.69
max 1.163e+04 2.479e+02 46.907 < 2e-16 ***
logEC50 1.098e+00 5.192e-02 21.154 < 2e-16 ***
n 1.089e+00 1.325e-01 8.216 2.70e-08 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 638.2 on 23 degrees of freedom
Number of iterations to convergence: 6
Achieved convergence tolerance: 6.254e-06
この表では、パラメーターの見積もりとともに標準誤差、t値、有意確率pが表示されています。ここでのt値およびpは、「パラメーターがゼロである」という帰無仮説のもとでの値です。つまり、baseのpが0.69ということは、「baseはゼロでないとは言えない」ということになります。他のパラメーターは有意水準0.1%で「ゼロではない」ということになりますが、あまり意味がありません。
信頼区間を求める
求めたパラメーターの信頼度を表す指標として、ここでは95%信頼区間を求めます。信頼区間の解釈は、「十分高い確率でパラメーターの真の値はこの範囲にある」といったところです。結果を見ながら具体的に説明します。関数confint()で求まる信頼区間は、左右対称で(そのように仮定しているということです)、データ数が多いときは2×Std.Err.ほどです。
confint(res)
2.5% 97.5%
base -1001.7114481 536.663112
max 11133.5587914 12172.634271
logEC50 0.9891411 1.203435
n 0.8555513 1.385857
例えば、baseの値は、見積もりの値では負の値になっていました。信頼区間を見てみると、-1001から537となっています。ここから、「nls()により得られた-154という値は、元のデータ(あるいはグラフ)から見積もったbase=280という値からして有意に異なるとはいえない」と言えます。つまり、今回データを用いたフィッティングでは負の値が出てしまっていますが、仮に真の値が280くらいであったとしても「たまたま」「偶然」でてしまう範囲だということです。
logEC50の95%信頼区間は、0.989から1.203とでています。これをEC50の信頼区間に変換すると、9.7nMから16nMとなります。
さて、baseの信頼区間がやや広く、推定の精度があまり良くないようですが、この理由は、低濃度側のデータが少ないことによると考えられます。つまり、今あるデータからはベースラインがどこか判断しきれないということです。もう1点でも低濃度側にデータを取れば、信頼区間は狭くなると考えられます。また、実験的にコントロールのwellがあり、あらかじめbaseが0となるように差し引いている場合は、base=0としてフィッティングを行います。
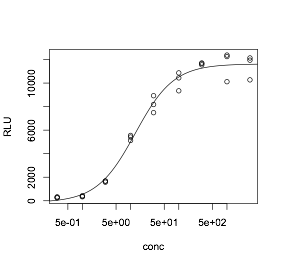
データにシグモイド曲線を重ね書きする
データに対する当てはまりの良さは、通常の使用ではグラフをみれば十分です。ここではデータをプロットしたグラフに曲線を描く方法を説明します。その前に、いくつかRの使い方を説明します。
まず、ここで使う関数predict()について簡単に説明します。例えば、濃度が5nMの時の理論上のRLUが知りたいとします。その場合は、predict(res, newdata=list(conc=5) とすれば3010.974と求まります。この関数は、nls()の結果resを受け取って、concが5の場合の値を返します。
次に、Rでのベクトルとその計算について簡単に説明します。seq(a,b, length=n)という関数は、aからbまでを等分するn点を返すという関数です。例えば、seq(0,6,length=4)の結果は、(0, 2, 4, 6)となります。また、10^seq(0, 6, length=4)の結果は、(1, 100, 10000, 1000000)といった具合です。
さて、本題に戻ります。まず、10^-2から10^4までを等分した100点のデータを作り、concpreに入れておきます。そして、lines(x,y)でグラフに曲線を重ね書きします。
concpre=10^seq(-2,4, length=100)
lines(concpre, predict(res, newdata=list(conc=concpre)))
n=3のデータをあらかじめ平均値とするか、そのままフィッティングするか?
パラメーターの値自体は同じ値となります。ただし、フィッティングの標準誤差と信頼区間が異なります。どちらの方法を用いるかは実験系によります(n=3が互いに独立だと見なしてよいかどうかが問題となります)が、基本的には平均する前のデータそのものを用いるべきです。同じサンプルを3回測定した場合等は、n=3とは見なしません(かならず平均値を用いる)。一般的には、96wellでのreplicateはn=3と見なしてよいようです。
Rによる非線形最小二乗法 (シグモイド編)
10/04/09